一、项目目标
本项目的目标不是简单地训练一个预测模型然后输出数字,而是构建一套可复现、可解释、低泄漏风险的月度用电量预测工作流。整套流程从数据更新开始,经过候选模型选择、重训预测、规则增强校正,最终形成经过审计验证的业务交付结果。
核心交付物是两个宽表文件:
new_data_202603_202612_yg_hainan_policy_model_method_province_total_predictions_wide.csv:包含 2026-05 到 2026-12 的预测值,是”模型基础预测 + 冻结规则增强链 + 汇总审计”后的发布结果。- 伴生文件额外拼接了 2026-03 和 2026-04 的实际电量,形成”实际 + 预测”的连续展示版本。
预测范围覆盖云南、广东、广西、海南、贵州五省,同时单独展示深圳作为广东省内城市预测。发布口径包含省级预测、深圳预测和五省合计预测。其中五省合计严格等于五个省预测值求和,深圳只作为城市展示,不重复计入五省合计。
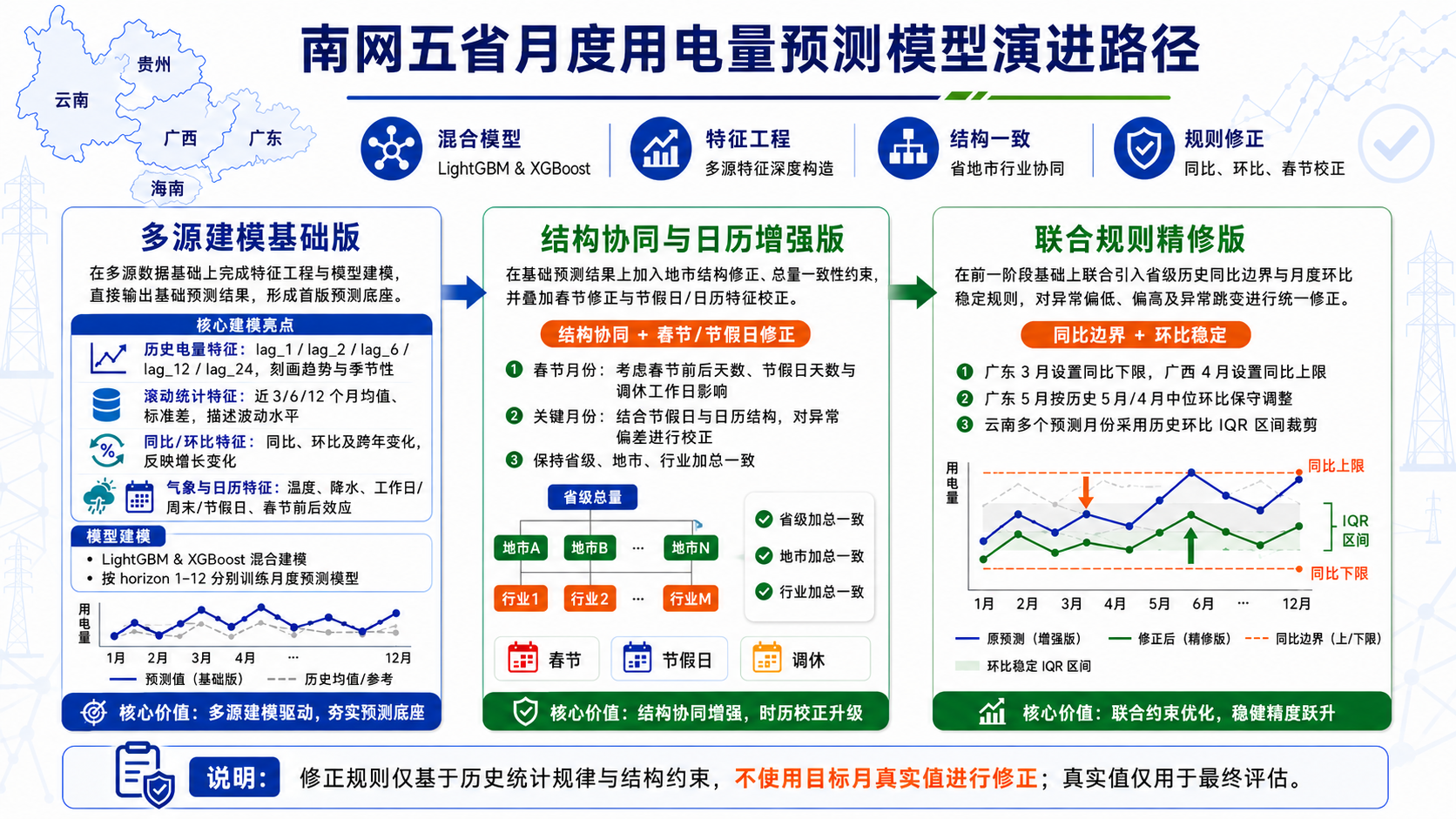 图:技术方案从 V1 到 V3 的迭代路径,展示了数据管线、模型选型、规则增强和审计体系的演进过程
图:技术方案从 V1 到 V3 的迭代路径,展示了数据管线、模型选型、规则增强和审计体系的演进过程
二、数据更新与预测边界
2.1 输入数据
本轮训练涉及三张核心数据表:
| 文件 | 说明 |
|---|---|
city_hydl_monthly_masked_all.csv | 主训练数据,包含城市-行业-月份粒度的历史用电量 |
city_weather_data.csv | 城市级月度天气特征(温度、降水、极端天气等) |
abnormal_dl_fluctuation_202511_202605_masked.csv | 异常波动外生变量,标识已知的目标月异常电量波动 |
训练截止月为 2026-04。训练数据中已经并入了 2026-03 和 2026-04 的实际用电量。预测起点(forecast origin)为 2026-04。
2.2 预测范围
模型实际生成 12 个 horizon,即 2026-05 到 2027-04。但本次发布只截取前 8 个月,即 2026-05 到 2026-12。
需要明确强调的是:未来目标月的实际电量标签从未被用于训练或校正预测结果。所有预测均为事前(ex-ante)或准实时(nowcast)性质,不包含任何前瞻偏差。
三、建模方式
3.1 行业聚合与底层序列
五省均使用 ABCD 行业聚合口径(series_scope=abcd)。底层序列按城市、行业分类和月份维度组织。模型首先在底层序列上独立训练,然后汇总得到省级预测。这种”自底向上”的聚合策略保留了城市-行业级别的结构信息。
3.2 直接多步预测
每个省、每个预测步长 horizon 单独训练一个直接多步模型。也就是说,horizon=1 到 horizon=12 分别训练独立模型,而不是使用递归滚动预测。直接多步策略避免了递归误差累积,但需要维护 12 × 省数量的模型实例。
3.3 目标变换
目标变量使用 log1p(target) 训练(即 log(1 + target))。预测完成后通过 expm1 还原回原始尺度。这一变换有助于稳定方差,并将预测值约束在非负范围。还原后的负值会被截断为 0。
3.4 五省模型配置
以下为每个省经过历史验证阶段固化的模型选型:
| 省份 | 算法 | 损失函数 | 样本权重 | 宏观特征 | 关键超参数 |
|---|---|---|---|---|---|
| 云南 | LightGBM | L2 | — | 未启用 | — |
| 广东 | LightGBM | Huber | √(电量) | 启用 | — |
| 广西 | LightGBM | L2 | — | 启用 | n_estimators=500, lr=0.025, num_leaves=11 |
| 海南 | LightGBM | Huber | √(电量) | 启用 | — |
| 贵州 | XGBoost | L2 | — | 启用 | n_estimators=500, lr=0.025 |
各省模型选型的差异来源于历史验证阶段对精度、鲁棒性和计算效率的综合权衡。例如,广东使用 Huber 损失以应对极端值,并使用 sqrt 电量权重使模型更关注高用电量月份;贵州选择 XGBoost 而非 LightGBM 是基于该省数据特征在验证窗口中的表现更优。
四、特征体系
模型使用的特征可分为以下九大类,总计覆盖约 120+ 维特征:
4.1 序列身份特征
series_id、城市编码 dsmc、行业编码 order_no、行业名称 hyflmc。这些特征帮助模型区分不同序列的模式差异。
4.2 滞后特征
lag_0、lag_1、lag_2、lag_3、lag_6、lag_12、lag_13、lag_24。涵盖从近邻到年周期的多层次滞后,捕捉短、中、长期自回归结构。
4.3 滚动统计
3、6、12 个月的滚动均值(rolling mean)和滚动标准差(rolling std)。这些统计量帮助模型感知局部的趋势和波动性变化。
4.4 增长率特征
环比增长率、同比增长率、两年增长率。增长率特征对经济周期和季节性变化敏感,是电力预测中的核心驱动因子。
4.5 汇总滞后特征
城市总量滞后特征和省级总量滞后特征。这些特征将来自更粗粒度的信息传递到底层序列,帮助捕捉区域整体趋势。
4.6 日历特征
月份、季度、周期编码(sin/cos)、当月天数、工作日天数、周末天数、法定节假日天数、调休工作日天数、春节所在月份标识、春节前后窗口标识、农历近似月份等。日历系统对用电行为有显著影响,尤其是春节效应对全国用电曲线产生年度最大偏移。
4.7 天气特征
月均温、最高温度、最低温度、风力、降雨天数、晴天、阴天、雾霾、雷暴、高温日数、低温日数、制冷度日(CDD)、采暖度日(HDD)等。天气特征解释了非经济驱动的大幅波动。
4.8 宏观特征
省级 GDP、全国 GDP、第二产业和第三产业 GDP 及其占比、人口、人均可支配收入、人均 GDP 等。云南本轮未启用宏观特征,其他四省启用。是否启用宏观特征取决于各省数据质量和验证阶段的消融实验结论。
4.9 异常波动特征
target_abnormal_dl_fluctuation 和 target_abnormal_available 两个字段。这些特征用于表达目标月份是否存在已知的异常电量波动(如政策限产、极端天气停产、检修等)。异常波动文件目前覆盖到 2026-05,后续月份缺失时填充为 0。
4.10 天气使用规则
天气特征有两个关键配置参数:
target_weather_mode=actual:目标月如果已有观测天气就使用观测天气,否则回退到城市月份气候均值。strict_climatology=True:在验证和回测阶段,严格使用预测起点之前的天气信息,避免引入前瞻偏差。这确保了模型评估反映的是真实的”可获取信息集”下的预测能力。
五、模型选择、验证与测试
5.1 验证框架
本项目不是每次发布时重新调参选模型,而是沿用历史验证阶段已经固化的每省最佳候选模型。模型选择遵循严格的时间线划分:
| 窗口 | 时间范围 | 用途 |
|---|---|---|
| 模型选择窗口 | 2024-03 至 2025-02 | 候选模型筛选与消融实验 |
| 最终测试窗口 | 2025-03 至 2026-02 | 最终评估,不参与调参 |
最终测试集不参与任何参数调整。候选模型中排除了使用”预测月真实气象”的泄漏风险版本,确保评估结果反映真实预测能力。
5.2 评估指标
准确率定义为:
Accuracy = 1 - |prediction - actual| / actual12 个月得分取月度准确率的算术平均值。同时计算 WMAPE(加权平均绝对百分比误差)作为补充指标。
5.3 历史验证结果
最终测试窗口的表现如下:
| 层级 | 平均准确率 | WMAPE |
|---|---|---|
| 五省省月 | 95.90% | 4.11% |
| 五省总量 | 96.84% | 3.06% |
这些指标来自历史验证阶段,不代表未来必然表现相同,但为当前模型框架的可信度提供了量化基准。
5.4 本轮训练策略
本轮产出阶段使用 skip_backtest,即不重新执行滚动回测。流程是冻结候选模型选择、更新训练数据到 2026-04、重新训练所有 horizon 模型,然后发布未来预测。这种策略在已有充分验证基础的前提下,能高效完成新一轮预测发布。
六、规则增强与校正链
最终发布结果不是模型原始输出,而是经过一系列增强规则校正后的产物。以下详述每个增强组件的设计动机和实际效果。
6.1 冻结残差层级校正(通用)
所有省份均启用了残差层级校正(residual hierarchy)。参数配置为:clip=0.12、prior=0.50、bottom=0.35。
工作原理:
- 基于历史训练行拟合底层残差先验分布;
- 对底层城市-行业预测施加残差修正;
- 修正后的底层结果汇总到省级;
- 省级融合结果 = (1 -
bottom) × 省级基础预测 +bottom× 底层汇总结果。
当底层候选结果与省级基础预测差距较大时,bottom 参数会限制底层权重不超过 35%,防止过激校正。这是模型从”纯数据驱动”走向”可约束校准”的关键机制。
6.2 云南直接残差模型
云南额外启用了 Ridge 直接残差模型,配置为 ridge_alpha=100、clip=0.08、weight=1.00。
最终云南结果的增强组件标签为 frozen_residual_hierarchy|yunnan_validation_direct,表示同时使用了残差层级校正和直接残差模型。在 2026-05 到 2026-12 中,云南相对基础模型约上调 6.8% 到 7.6%。
这一校正幅度较大,原因是云南消耗电量数据中存在结构性低估趋势,验证集上的残差分析表明系统性的正向偏差需要被补偿。
6.3 广西月份融合
广西使用 month fusion 策略,即按目标月份融合”残差层级候选”和”直接残差模型”两个组件。具体权重分配:
| 月份 | 残差层级候选权重 | 直接残差权重 |
|---|---|---|
| 2026-05 | 0.2 | 0.8 |
| 2026-06 | 0.9 | 0.1 |
| 2026-07 | 0.1 | 0.9 |
| 2026-08 | 0.0 | 1.0 |
| 2026-09 至 2026-12 | 0.0 | 1.0 |
这种逐月差异化的融合策略反映了验证阶段观察到的季节性校正需求变化。最终广西相对基础模型约上调 1.35% 到 5.85%。
6.4 广东恢复上限
历史规则中存在广东 3 月到 4 月恢复上限,参数 guangdong_mar_apr_recovery_cap=1.0502256394。该规则用于限制广东在春季生产恢复期(3-4 月)的过度上调。
但本轮发布只输出 2026-05 到 2026-12,因此这个 cap 在当前文件中没有实际触发。保留该规则是为了维持系统一致性,当后续扩展到覆盖 3-4 月时无需重新配置。
6.5 广东、海南、贵州
这三个省份没有额外直接残差替换,主要使用冻结残差层级校正作为唯一增强机制。调整幅度相对较小:
| 省份 | 调整幅度 |
|---|---|
| 广东 | +0.42% 至 +0.74% |
| 海南 | +0.39% 至 +0.60% |
| 贵州 | +0.10% 至 +0.70% |
这些较小幅度的校正说明三省的基础模型预测在历史验证中已经较为准确。
6.6 深圳缩放
深圳预测来自广东底层城市预测数据。最终深圳值按以下公式计算:
深圳最终预测 = 深圳基础预测 × (广东增强后省级预测 / 广东基础省级预测)即深圳的预测值随广东省级校正同比例缩放。深圳只用于单独展示,不计入五省合计。
6.7 增强效果总结
在 2026-05 到 2026-12 的预测窗口中,规则增强后五省总量相对基础模型每月上调约 1.93% 到 3.21%。主要贡献来自云南(约 +7%)和广西(约 +1% 到 +6%),广东、海南、贵州的调整幅度较小。
七、最终输出与审计
7.1 五省合计预测值
以下为 2026-05 到 2026-12 的五省合计发布结果(单位:百亿千瓦时):
| 月份 | 五省合计预测 |
|---|---|
| 2026-05 | 4.670587 |
| 2026-06 | 4.861001 |
| 2026-07 | 5.194121 |
| 2026-08 | 5.229022 |
| 2026-09 | 4.987736 |
| 2026-10 | 4.880431 |
| 2026-11 | 4.693130 |
| 2026-12 | 4.816220 |
呈现典型的夏高冬低的季节性模式。7-8 月为全年用电高峰,与空调制冷负荷的峰值吻合;11 月为低谷。
7.2 汇总审计
sum_check 验证显示:五省合计与五个省预测求和的最大差异约为 8.88e-16,属于浮点运算误差,证明汇总口径一致,深圳未被重复计入。
7.3 交付规范
每次发布均保留以下输出格式:
- wide:宽表格式,行=省份/城市,列=月份
- long:长表格式,便于数据库和 BI 工具导入
- metadata:记录训练配置、模型候选、校正参数、文件路径
- sum_check:校验省级求和与合计列是否一致
这种多格式输出确保了结果的可审计性和下游消费的便利性。
八、方法亮点
8.1 泄漏控制
本项目在数据使用上设置了多重防线:
- 候选模型选择阶段排除使用预测月真实气象的版本,从源头避免前瞻泄漏;
- 最终测试窗口(2025-03 到 2026-02)不参与任何调参;
- 未来目标月的实际电量标签绝不进入训练或校正流程;
strict_climatology=True确保回测中使用的总是预测起点前可获取的信息。
8.2 可解释增强链
最终结果不是黑箱输出,而是由基础模型、残差层级校正、云南直接残差模型、广西月份融合、深圳缩放等组件逐层形成。每一层的变换都被记录在 metadata 中,可以追溯到任意省份、任意月份的校正来源。
8.3 可审计交付
每次发布都保留 wide、long、metadata、sum_check 四种格式的输出。通过 metadata 可以追踪数据来源、训练配置、模型候选和校正幅度;通过 sum_check 可以快速验证汇总口径的正确性。
九、局限性与后续改进
9.1 天气信息的前瞻性问题
本轮目标月天气在可用时使用观测天气(target_weather_mode=actual),否则回退气候均值。这意味着当前结果是准实时预测,而非纯粹的事前预测。在区分”事前预测”、“准实时预测”和”事后诊断”三种场景时,需要明确标注天气信息的时效性。
9.2 异常波动文件的覆盖范围
异常波动文件目前只覆盖到 2026-05。后续月份缺失时填充为 0,这意味着 2026-06 以后的预测中可能缺少对已知重大事件的反映。后续应建立异常波动文件的持续更新机制。
9.3 无实时回测
本轮产出阶段未重新执行滚动回测,而是沿用历史验证选型后重训。如果数据分布发生显著变化(如经济结构转型、极端天气频发),历史验证阶段的模型选择决策可能需要重新评估。
9.4 路径可移植性
文件目录在历史迭代中曾被整理移动,metadata 中记录的历史绝对路径可能与当前文件夹位置不完全一致。后续复现或自动化部署时需要统一路径配置,或使用相对路径引用。
9.5 后续改进方向
- 建立自动化的数据新鲜度监控,当训练数据更新后自动触发重训;
- 引入概率预测和不确定性量化,为业务决策提供置信区间;
- 探索时间序列大模型(如 Chronos-2、GTT)在省级聚合层面的直接预测能力,对比当前”底层建模再汇总”的策略;
- 完善异常波动文件的生成流程,建立从政策公告到数据特征的映射管线。